매개변수 갱신
신경망 학습의 목적은 매개변수의 최적값을 찾는 문제(손실함수의 값을 가능한 한 낮추는 매개변수를 찾는 것)이다.
이러한 문제를 푸는 것을 최적화(optimization)이라 한다.
확률적 경사 하강법(SGD: Stochastic Gradient descent)

- SGD는 단순하고 구현도 쉽지만, 문제에 따라서 비효율적일 때가 있다.
- 비등방성(anisotropy)함수(방향에 따라 기울기가 달라지는 함수)에서는 탐색 경로가 비효율적이다.
코드
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
모멘텀(Momentum)
기울기 방향으로 힘을 받아 물체가 가속된다는 물리법칙을 이용한 기법
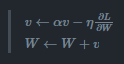
- v 는 물리에서의 속도(velocity)에 해당
- alpha v항은 물체가 아무런 힘을 받지 않을때 서서히 하강시키는 역할(alpha는 0.9등의 값으로 설정)
코드
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
AdaGrad

- 각각의 매개변수에 *학습률 감소(learning rate decay) 맞춤형 값을 만든다.
- *학습률 감소(learning rate decay) : 학습을 진행하며 학습률을 점차 줄여가는 방법
- h는 기울기값을 제곱하여 누적하고 매개변수를 갱신할 때 1 \over \sqrt h를 곱해 학습률을 조정한다.
- 학습을 진행할수록 갱신 강도가 약해져 어느 순간 갱신량이 0이 된다.(RMSProp 방법은 이 문제를 개선해 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영한다)
코드
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
Adam
- Momentum과 AdaGrad를 융합한 방법이다.
- 하이퍼파라미터의 '편향 보정'이 진행된다.
- 논문(http://arxiv.org/abs/1412.6980v8)
코드
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)

- 해당 함수에 대해서는 AdaGrad가 가장 나아보이지만, 문제에 따라 뛰어난 기법은 다르다.
- 학습률 등의 하이퍼파라미터를 어떻게 설정하느냐에 따라서도 결과가 바뀐다.
'AI > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| CNN 합성곱 계층 (0) | 2024.07.13 |
|---|---|
| 학습 관련 기술 정리 (0) | 2024.07.13 |
| 배치 정규화 (0) | 2024.07.13 |
| 가중치의 초깃값 (0) | 2024.07.13 |
| 역전파(Backpropagation) (0) | 2024.06.12 |